The following steps assume that the applications running in the Kubernetes cluster
expose Prometheus metrics. To ingest other metric types such as StatsD, refer to
Ingest additional metrics.
- Create an API token.
- Define the Collector manifest.
- Create a Kubernetes secret.
- Install the Collector.
- Verify the Collector.
Create an API token
To interact with the Collector, you must create a service account. Chronosphere recommends creating a restricted service account with a write-only scope. Use the generated API token in your KubernetesSecret to authenticate
with the Collector.
Define the Collector manifest
- Download the example manifest.
-
Locate the
spec.template.spec.containers.imageYAML collection and changevVERSION_NUMBERto the version of the Collector you want to install. For example,v0.116.0:Chronosphere supports Chronosphere Collector versions for a year from release. You can find a full list of versions and release dates in the Collector release notes located in the Chronosphere Observability Platform. To view the release notes, in the navigation menu select More information > Release notes, and then click the Collector tab. -
Modify any configuration values in the
ConfigMapbased on your needs. Refer to the Collector configuration for details about configuration options.
Create a Kubernetes secret
Create a KubernetesSecret that includes the API token from your service account,
plus a custom domain address.
-
Add
base64encoding to your domain name and API token:Replace the following: -
Copy the values that output to your terminal, which you add as part of your
Kubernetes
Secretin the next step. -
In your
chronocollector.yamlfile, locate the following YAML collection and replace values foraddressandapi-tokenwith the encoded values that you copied from your terminal.Another option is to add theADDRESSandAPI_TOKENdirectly to the Kubernetes cluster usingkubectl: -
Save and close your
chronocollector.yamlfile.
Install the Collector
To install the Collector, apply thechronocollector.yaml manifest that you
configured. When using a
DaemonSet,
you must install the Collector on each node in a cluster.
-
Apply the manifest.
-
Confirm that the
DaemonSetis up and running, and view the logs of the pod: -
View the pod logs to ensure there are no errors:
Replace
POD_NAMEwith the name of the Kubernetes pod where your Collector instance is running.
Verify the Collector
After installing the Collector, verify it’s sending metrics to your Observability Platform tenant:- Open Observability Platform and in the navigation menu select Explorers > Metrics Explorer.
-
Enter the following query in the query field.
-
Click Run.
The name of your Collector instance returned from the
kubectl logscommand displays in the table of metrics:
Install the Collector using a Deployment
If you use Prometheus service discovery, deploy the Collector as a standalone Deployment. This implementation avoids every Collector duplicating scrapes to all endpoints defined in the Prometheus service discovery configuration. The instructions for deploying the Collector as a Deployment are the same as for a DaemonSet, except you use this manifest.Install the Collector as a sidecar
Some environments (like AWS Fargate) restrict users from deploying an app as aDaemonSet and require deploying the Collector as a sidecar alongside other
containers. You can also use a sidecar configuration for more control over resource
utilization for particularly high cardinality scrape targets.
If your app is already running as a container in a Pod, you can add the Collector as
another container in the same Pod. The instructions for deploying the Collector as a
sidecar are the same as for a DaemonSet, except you use
this manifest
and add the Collector as another container to the spec.template.spec.containers
block of the manifest, along with any other Kubernetes resources your app requires.
Configure service discovery
After configuring and installing the Collector, configure Kubernetes annotations so that the Collector can start scraping the Pods in your Kubernetes cluster. If you installed the Collector as a Deployment or as a sidecar service, configure service discovery usingServiceMonitors or Prometheus service discovery.
Modify Collector resource usage
After deploying the Collector, you can modify resource usage depending on various inputs, including, but not limited to:- Amount of scraped metrics
- Scrape interval of each target
- Number of metric labels
- Total length of the label strings
This information is both a starting point and an upper limit. Tune your Collectors
after their deployments, based on practical usage.
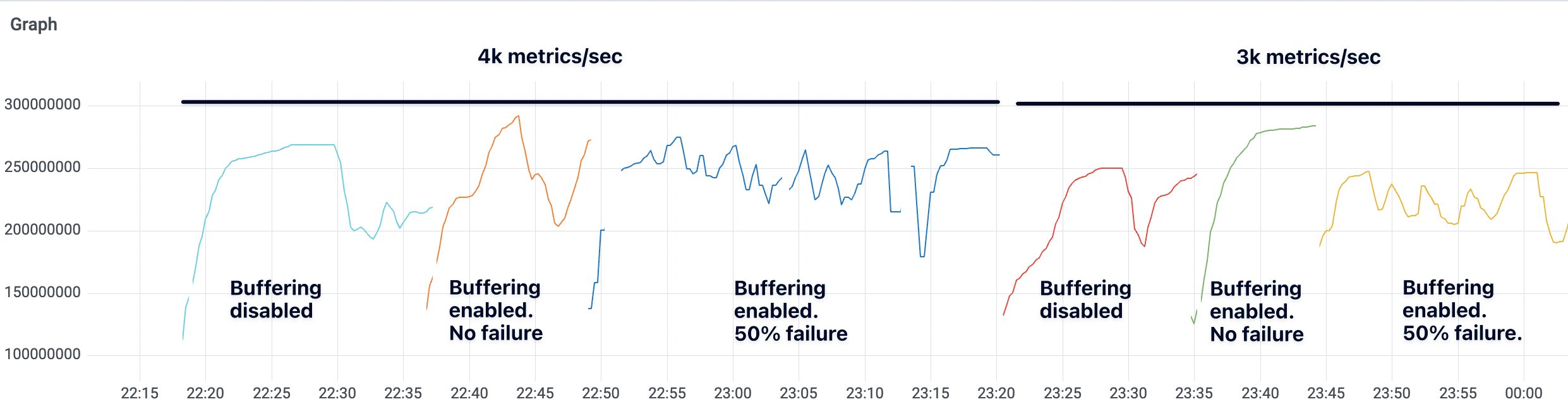
Ingestion buffering
Enabling ingestion buffering doesn’t have any substantial impact on memory usage. The following graph displays the memory usage of a Collector instance handling different input data volume (4k and 3k metrics per second, respectively). The memory usage doesn’t change significantly after enabling the buffering feature or increasing the failure rate from 0% to 50%.